Большие языковые модели (LLM) совершили революцию в области обработки естественного языка, но их потенциал выходит далеко за рамки стандартных задач, таких как написание текстов или ответов на вопросы. Продвинутые инженеры могут раскрыть скрытые возможности LLM, применяя передовые техники “prompt engineering” и специализированного обучения. В этой статье мы рассмотрим, как выжимать из LLM решения для сложных задач: генерация специализированного кода, анализ сложных данных, создание нестандартных интерактивных приложений. Мы покажем, как обходить ограничения стандартных LLM и раскрыть их потенциал, с практическими примерами и советами по эффективной настройке.
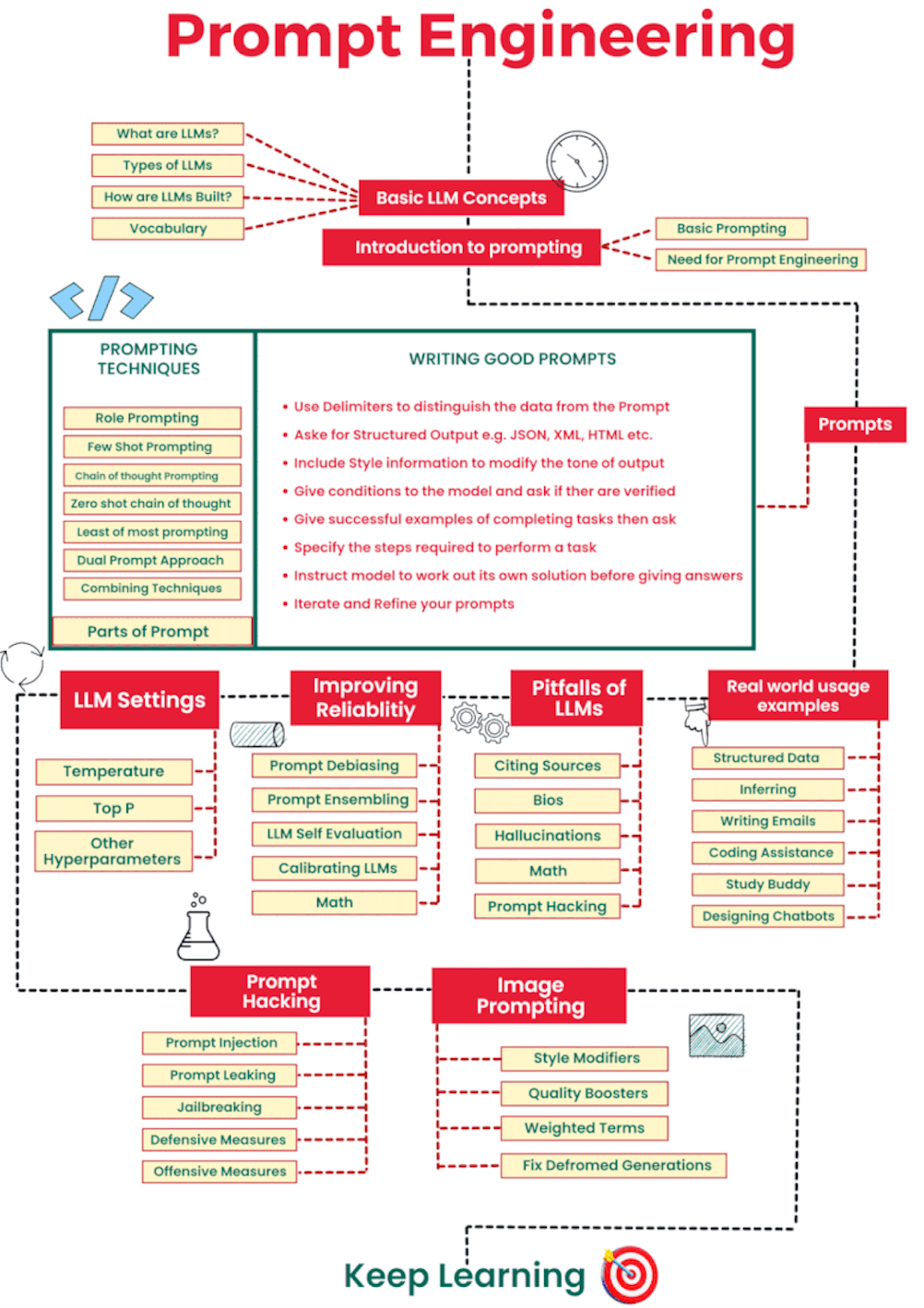
Prompt Engineering: Искусство управления LLM
Prompt engineering – это больше, чем просто написание запроса. Это искусство формулирования задачи таким образом, чтобы LLM предоставила наиболее точный и полезный результат. Вот несколько передовых техник:
-
Few-shot learning:
Предоставьте LLM несколько примеров желаемого результата. Это помогает модели понять контекст и адаптироваться к конкретной задаче. Например, если вы хотите, чтобы модель генерировала SQL-запросы на основе сложного описания данных, дайте ей несколько примеров запросов и соответствующих описаний.
-
Chain-of-Thought (CoT) prompting:
Этот метод побуждает LLM рассуждать вслух, показывая процесс мышления. Полезно для задач, требующих логических выводов или многоступенчатых расчетов. Попросите LLM объяснить каждый шаг решения, прежде чем предоставить окончательный ответ. -
Role-Playing (ролевая игра):
Заставьте LLM сыграть определенную роль – эксперта в конкретной области, опытного программиста, аналитика данных. Это может улучшить качество ответов, поскольку модель будет опираться на знания, связанные с этой ролью. -
Constrained Generation (ограниченная генерация):
Укажите точные ограничения на формат и структуру генерируемого текста. Это важно для создания специализированного кода или формальных документов. Используйте ключевые слова, шаблоны или ограничения по длине.
Специализированное Обучение: Подстраиваем LLM под Ваши Потребности
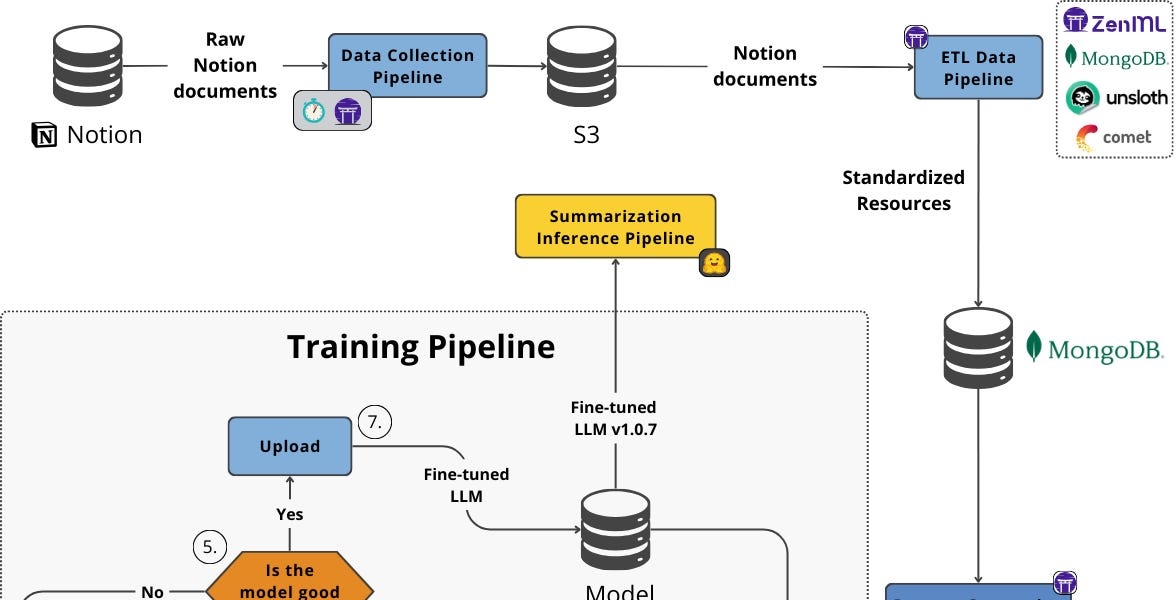
В то время как prompt engineering может улучшить результаты для многих задач, в некоторых случаях требуется более глубокая настройка. Специализированное обучение позволяет адаптировать LLM к конкретной области знаний или типу данных.
-
Fine-tuning (тонкая настройка):
Обучите LLM на небольшом, но качественном наборе данных, специфичном для вашей задачи. Это гораздо менее затратно, чем обучение модели с нуля, но позволяет значительно улучшить производительность. Например, если вы хотите создать LLM для анализа медицинских заключений, тонкая настройка на корпусе медицинских текстов даст гораздо лучшие результаты, чем использование стандартной модели. -
Reinforcement Learning from Human Feedback (RLHF) (обучение с подкреплением на основе обратной связи от человека):
Используйте отзывы от человека для обучения модели, как генерировать более предпочтительные ответы. Этот метод особенно эффективен для задач, где субъективное качество ответа играет важную роль, например, в создании чат-ботов.
-
Adapter Modules (модули-адаптеры):
Вместо обучения всей модели, обучите небольшие адаптерные модули, которые добавляются к существующей LLM. Это позволяет быстро и эффективно адаптировать модель к новым задачам, не затрагивая ее основную архитектуру.
Примеры Передовых Приложений
Давайте рассмотрим несколько примеров того, как продвинутые инженеры используют LLM для решения сложных задач.
-
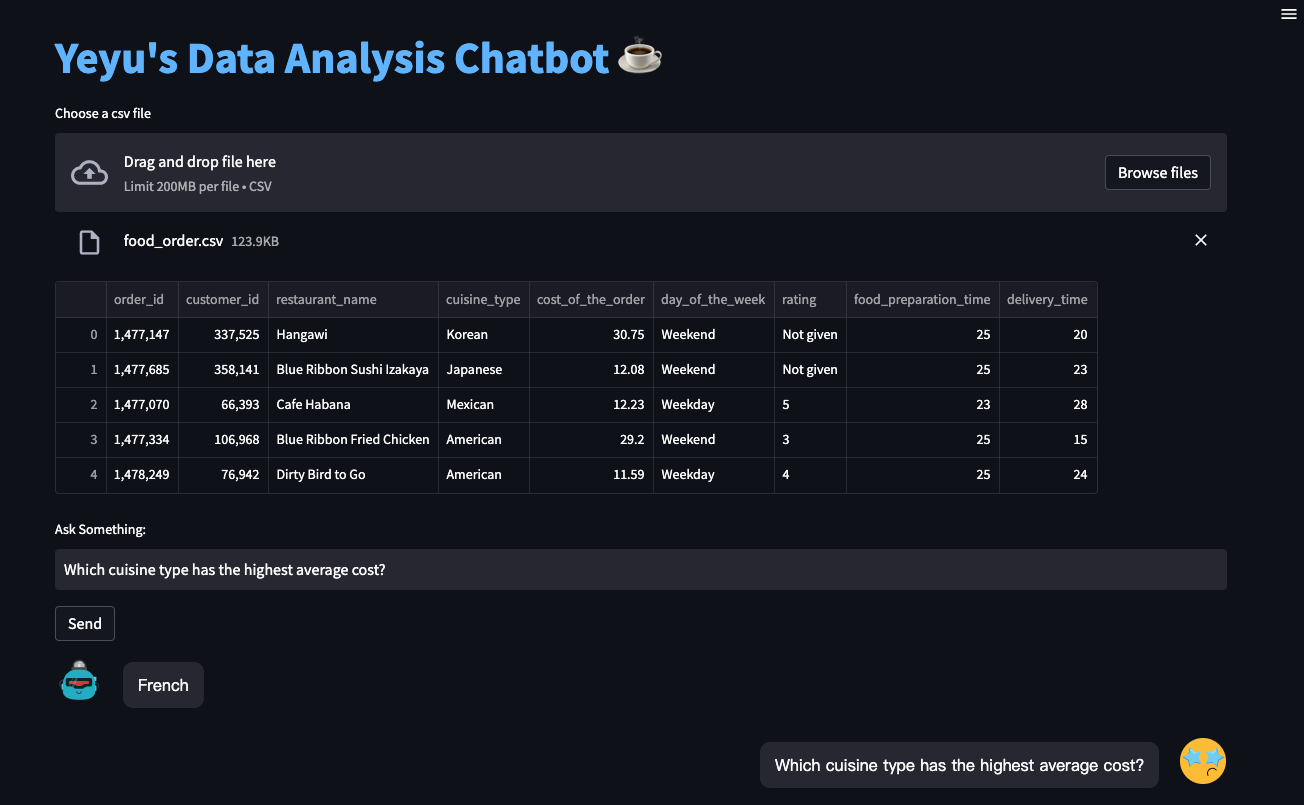
Генерация специализированного кода:
Используйте LLM для автоматической генерации кода на основе естественного языка. Например, можно создать систему, которая генерирует SQL-запросы на основе сложного описания данных или создает прототипы веб-приложений на основе диаграммы пользовательского интерфейса. CoT prompting может быть чрезвычайно полезен здесь, помогая LLM рассуждать о логике кода.
-
Анализ сложных данных:
Используйте LLM для анализа больших объемов неструктурированных данных, таких как медицинские заключения, юридические документы или социальные сети. Используйте few-shot learning, чтобы научить модель извлекать конкретную информацию и определять закономерности.
-
Создание интерактивных приложений:
Используйте LLM для создания чат-ботов, виртуальных ассистентов и других интерактивных приложений. RLHF может помочь создать более естественные и привлекательные интерфейсы.
-
Автоматизация научных исследований:
LLM могут быть использованы для автоматизации процесса анализа научных статей, извлечения ключевой информации, формулирования гипотез и даже написания научных отчетов.
Советы по Эффективной Настройке
Настройка LLM – это итеративный процесс, требующий экспериментов и анализа результатов. Вот несколько советов:
-
Начните с простого:
Не пытайтесь решить слишком сложные задачи сразу. Начните с простых примеров и постепенно усложняйте задачу. -
Экспериментируйте с различными техниками:
Попробуйте разные методы prompt engineering и специализированного обучения, чтобы найти наиболее эффективный подход. -
Используйте метрики:
Определите конкретные метрики для оценки качества результатов и используйте их для сравнения различных подходов. -
Итеративно улучшайте:
Постоянно анализируйте результаты и вносите коррективы в процесс настройки.
Раскрытие скрытого потенциала LLM требует глубокого понимания принципов их работы и готовности к экспериментам. Используя передовые техники prompt engineering и специализированного обучения, продвинутые инженеры могут создавать инновационные решения для самых сложных задач.
#LLM #ИскусственныйИнтеллект #PromptEngineering #МашинноеОбучение #ГенеративныйAI #Технологии #Программирование #DataScience #AI #AIdevelopment
Добавить комментарий