Python – язык, который любят за его читаемость и простоту. Однако, даже при использовании мощных оптимизированных библиотек, таких как NumPy, Pandas и SciPy, ваш код может работать заметно медленнее, чем хотелось бы. Проблема часто не в самих библиотеках, а в том, как вы их используете.
Распространенные ошибки и как их исправить
Давайте рассмотрим наиболее частые причины медленного Python-кода и способы их устранения. Мы будем использовать реальные примеры, чтобы сделать объяснения более понятными.
1. Неэффективное использование циклов
Циклы – это основа многих программ, но в Python они могут быть узким местом. Использование стандартных циклов
for
и
while
для операций над массивами данных значительно медленнее, чем использование векторизованных операций NumPy.

Пример: Вычисление квадратов элементов списка.
# Плохой способ (использование цикла for)
import time
data = list(range(1000000))
start_time = time.time()
result = []
for x in data:
result.append(x * x)
end_time = time.time()
print(f"Время выполнения цикла: {end_time - start_time} секунд")
# Хороший способ (использование NumPy)
import numpy as np
start_time = time.time()
data = np.array(list(range(1000000)))
result = data * data
end_time = time.time()
print(f"Время выполнения NumPy: {end_time - start_time} секунд")
Как видите, NumPy выполняет задачу значительно быстрее благодаря векторизации. Всегда старайтесь избегать явных циклов, если это возможно, и используйте векторизованные операции.
2. Неправильный выбор структур данных
Выбор правильной структуры данных критичен для производительности. Например, использование списков для поиска элементов может быть медленным, особенно при больших объемах данных. Вместо этого, используйте множества (
set
) или словари (
dict
) для быстрого поиска.
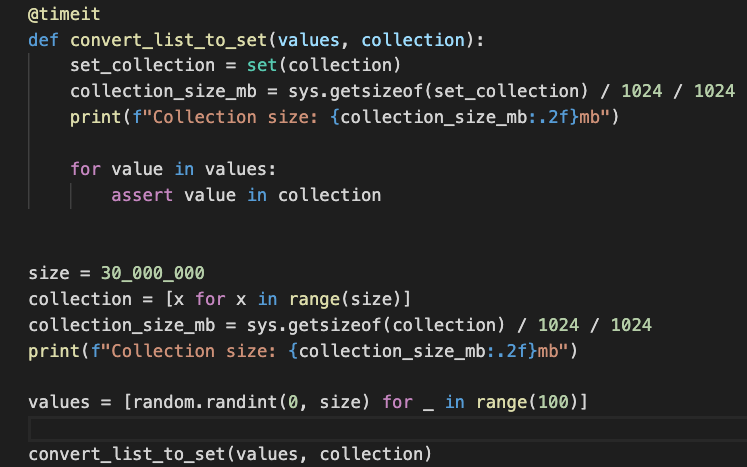
Пример: Поиск элемента в списке и во множестве.
import time
data_list = list(range(100000))
data_set = set(range(100000))
search_value = 99999
# Поиск в списке
start_time = time.time()
found = False
for x in data_list:
if x == search_value:
found = True
break
end_time = time.time()
print(f"Время поиска в списке: {end_time - start_time} секунд")
# Поиск во множестве
start_time = time.time()
found = search_value in data_set
end_time = time.time()
print(f"Время поиска во множестве: {end_time - start_time} секунд")
Множества обеспечивают поиск за O(1) в среднем, в то время как списки требуют O(n) времени. Выбор структуры данных напрямую влияет на сложность алгоритма.
3. Проблемы с памятью
Неэффективное управление памятью может привести к замедлению работы программы. Например, создание больших копий данных в памяти может быть дорогостоящим. Используйте генераторы (
yield
) и избегайте ненужных копий.
Пример: Создание списка чисел и использование генератора.
# Плохой способ (создание списка)
data = [x for x in range(1000000)] \# Создает список в памяти
# Хороший способ (использование генератора)
def generate_data(n):
for i in range(n):
yield i
data_generator = generate_data(1000000) \# Не создает список в памяти
Генераторы создают значения “на лету”, что позволяет экономить память, особенно при работе с большими объемами данных.
4. Профилирование кода
Чтобы точно определить узкие места в вашем коде, используйте профилировщики. Модуль
cProfile
в Python позволяет измерить время выполнения каждой функции и определить, какие из них являются самыми медленными.
import cProfile
def my_function():
\# Ваш код
pass
cProfile.run('my_function()')
Профилировщик покажет, сколько времени занимает каждая функция, что поможет вам сосредоточиться на оптимизации самых проблемных участков кода.
5. Использование правильных библиотек и функций
Изучите документацию используемых библиотек. Часто они предоставляют специализированные функции, оптимизированные для конкретных задач. Например, Pandas предоставляет множество функций для работы с данными, которые значительно эффективнее, чем написание собственного кода.
Заключение
Оптимизация Python-кода – это непрерывный процесс. Понимание основных принципов, использование правильных структур данных, избежание ненужных циклов и профилирование кода – все это поможет вам существенно повысить производительность ваших программ. Не забывайте, что даже небольшие изменения могут привести к значительным улучшениям. Регулярно оценивайте производительность вашего кода и ищите способы его оптимизации.
#python #оптимизация #производительность #numpy #pandas #профилирование #структуры_данных #алгоритмы
Добавить комментарий