В мире Data Science, где Python является основным инструментом, легко застрять в использовании одних и тех же, хорошо известных библиотек. Pandas, Scikit-learn, Matplotlib – это фундамент, но для повышения эффективности и получения более глубоких инсайтов стоит расширить свой инструментарий. Эта статья представляет пять менее известных, но невероятно полезных Python-библиотек, которые помогут вам сэкономить время и улучшить качество анализа данных.
-
imbalanced-learn: Мастерство работы с несбалансированными данными
Несбалансированные данные – распространенная проблема в Data Science, когда один класс представлен гораздо меньше, чем другой (например, обнаружение мошеннических транзакций, где мошеннических операций значительно меньше, чем нормальных). Стандартные алгоритмы машинного обучения могут быть предвзяты в пользу доминирующего класса, что приводит к плохой производительности на миноритарном классе.
imbalanced-learn
предлагает широкий спектр техник для решения этой проблемы.
Что делает:
Эта библиотека предоставляет методы передискретизации (oversampling и undersampling) для создания более сбалансированного набора данных. Вы можете использовать такие методы, как SMOTE (Synthetic Minority Oversampling Technique) для генерации синтетических примеров миноритарного класса или RandomUnderSampler для случайного удаления примеров доминирующего класса.
Пример:
from imblearn.over_sampling import SMOTE
import pandas as pd
# Предположим, у вас есть DataFrame 'df' с несбалансированными данными
# 'target' - имя колонки с целевой переменной
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X, y)
# X_resampled и y_resampled теперь содержат передискретизированные данные
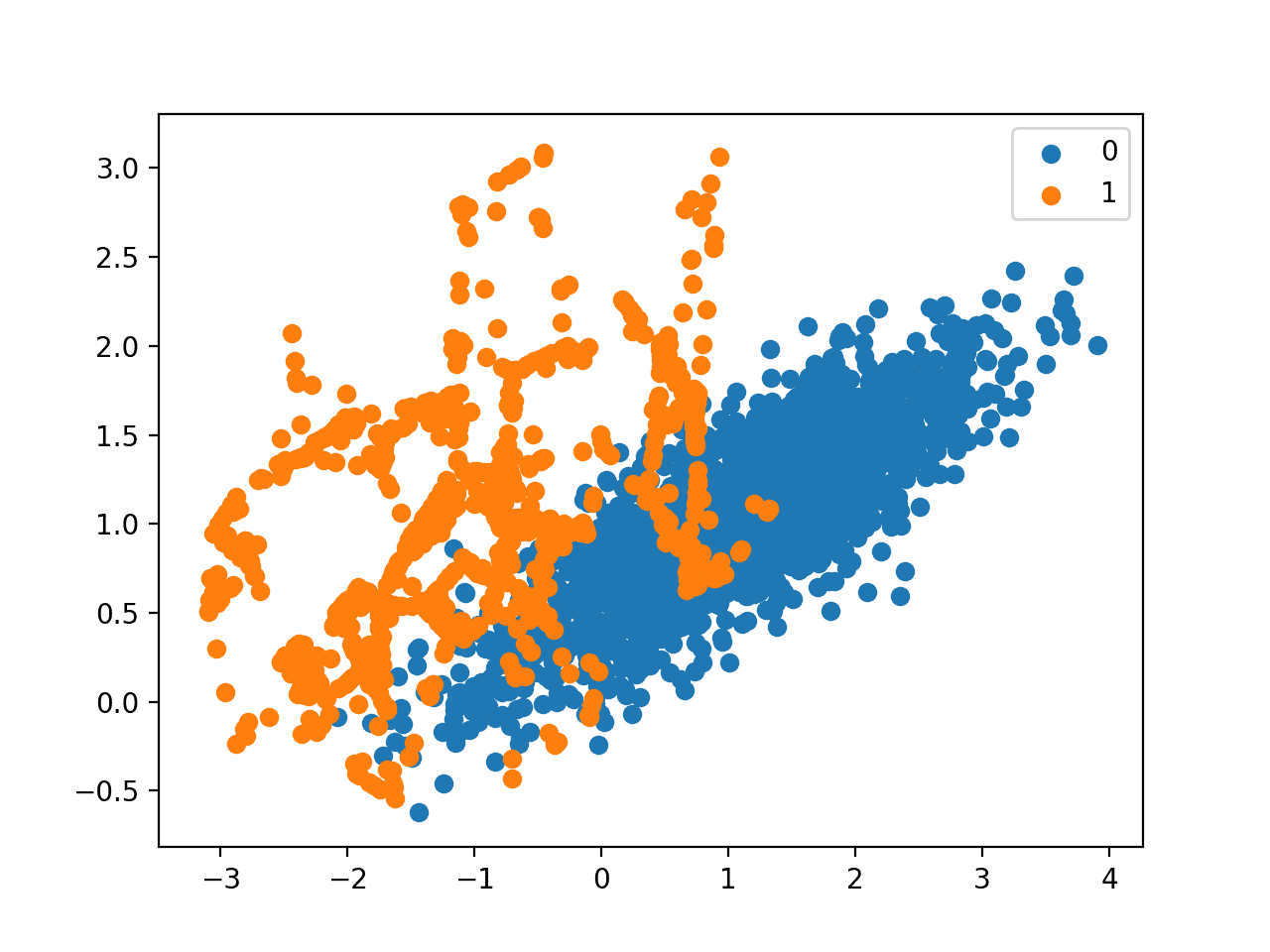
Почему это полезно:
imbalanced-learn
позволяет создавать более точные и надежные модели, особенно в задачах, где важно правильно предсказывать миноритарный класс.
2. dtale: Интерактивный анализ данных как в Excel, но лучше
Pandas – отличный инструмент для манипуляции данными, но для быстрого интерактивного анализа часто не хватает удобства.
dtale
– это веб-приложение, которое предоставляет интерактивный интерфейс для просмотра и анализа DataFrame Pandas. Это как электронная таблица, но с мощными возможностями фильтрации, сортировки, агрегации и визуализации.
Что делает:
dtale
позволяет фильтровать данные, сортировать их по различным критериям, вычислять агрегированные показатели, создавать гистограммы и другие визуализации прямо в браузере. Он также поддерживает отображение информации о пропущенных значениях и выбросах.
Пример:
import dtale
import pandas as pd
# Создаем DataFrame
data = {'col1': [1, 2, 2, 2, 2], 'col2': ['A', 'B', 'B', 'C', 'C']}
df = pd.DataFrame(data)
# Запускаем dtale с DataFrame
dtale.show(df)
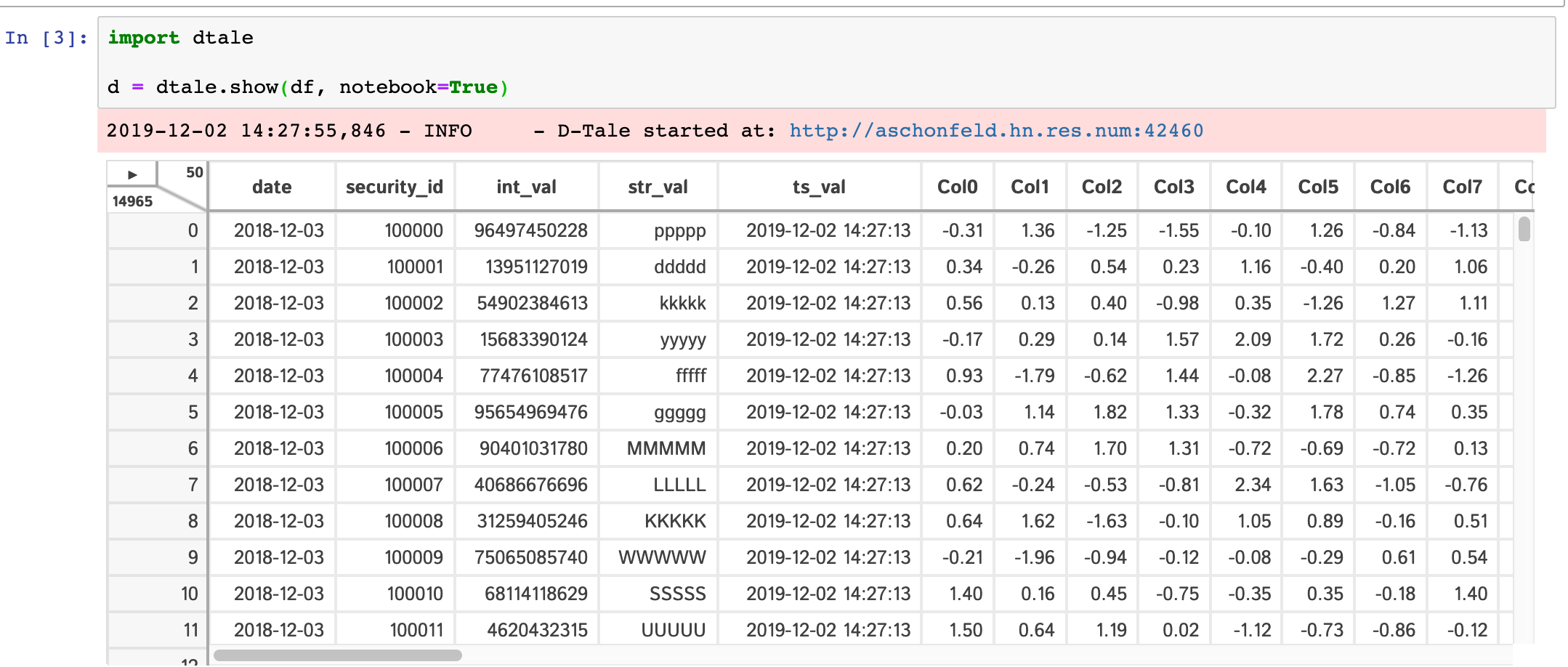
Почему это полезно:
dtale
ускоряет процесс исследования данных, позволяя быстро находить закономерности и аномалии, не покидая среды разработки.
3. relational: Манипуляции с данными как с базами данных
Если вы привыкли работать с базами данных,
relational
может стать настоящим открытием. Эта библиотека предоставляет декларативный API для манипулирования DataFrame Pandas, используя синтаксис, напоминающий SQL.
Что делает:
Вы можете выполнять операции, такие как фильтрация, агрегация, группировка, соединение и вычисление оконных функций, используя знакомый синтаксис, что делает код более читаемым и выразительным.
Пример:
import relational
import pandas as pd
# Создаем DataFrame
data = {'category': ['A', 'A', 'B', 'B', 'C'], 'value': [10, 15, 20, 25, 30]}
df = pd.DataFrame(data)
# Выбираем строки, где category равно 'A'
result = df.relational.select(df, where=['category == "A"'])
# Вычисляем среднее значение value для каждой категории
result = df.relational.aggregate(df, by='category', aggregate=['mean(value)'])
Почему это полезно:
relational
делает код более понятным и удобным для сопровождения, особенно если вы знакомы с SQL.
-
category_encoders: Расширенные методы кодирования категориальных переменных
Scikit-learn предлагает базовые методы кодирования категориальных переменных (OneHotEncoding, LabelEncoding), но
category_encoders
предоставляет гораздо более широкий спектр возможностей, включая Target Encoding, Leave-One-Out Encoding и другие продвинутые техники.
Что делает:
Эти методы позволяют преобразовать категориальные переменные в числовые, учитывая целевую переменную, что может улучшить производительность моделей машинного обучения.
Пример:
import category_encoders as ce
import pandas as pd
# Создаем DataFrame
data = {'category': ['A', 'B', 'A', 'C', 'B'], 'value': [10, 4, 2, 1, 5]}
df = pd.DataFrame(data)
# Используем Target Encoding
encoder = ce.TargetEncoder(cols=['category'])
df['category_encoded'] = encoder.fit_transform(df['category'], df['value'])
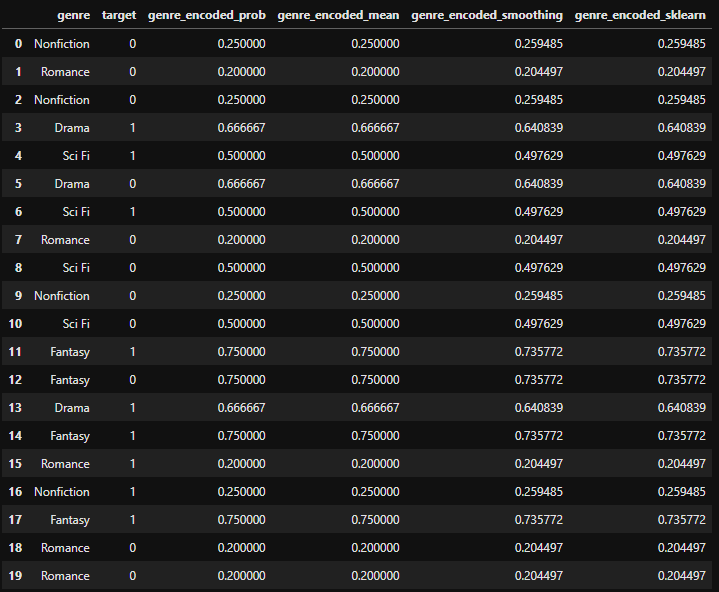
Почему это полезно:
category_encoders
позволяет получить более точные прогнозы, особенно в задачах с категориальными переменными, которые оказывают существенное влияние на результат.
5. missingno: Визуализация пропущенных данных
Пропущенные данные – распространенная проблема, и
missingno
предлагает удобные инструменты для визуализации их распределения и взаимосвязей. Вместо ручного подсчета и построения графиков,
missingno
позволяет быстро получить представление о структуре пропущенных значений.
Что делает:
Эта библиотека предоставляет такие визуализации, как матрица пропущенных значений, тепловая карта и гистограмма пропущенных значений.
Пример:
import missingno as msno
import pandas as pd
# Загружаем DataFrame с пропущенными данными
df = pd.read_csv("your_data.csv")
# Строим матрицу пропущенных значений
msno.matrix(df)
# Строим тепловую карту пропущенных значений
msno.heatmap(df)
Почему это полезно:
missingno
ускоряет процесс очистки данных и помогает выявить закономерности в пропущенных значениях, что может быть важно для выбора стратегии их обработки.
Эти пять библиотек – лишь небольшая часть огромного арсенала инструментов, доступных для Data Science на Python. Изучение и применение новых библиотек поможет вам стать более эффективным аналитиком данных и находить более глубокие инсайты.
#Python #DataScience #Библиотеки #Pandas #МашинноеОбучение #АнализДанных #Инструменты #Программирование
Добавить комментарий