Переобучение – бич машинного обучения. Мы все с этим сталкивались: модель идеально справляется с тренировочными данными, но проваливается на тестовых. Нейронные сети и случайные леса – мощные инструменты, но они не застрахованы от этой проблемы. Что делать, если стандартные методы регуляризации (L1, L2, dropout) не дают ожидаемого результата? В этой статье мы рассмотрим несколько “забытых” или менее популярных техник машинного обучения, которые могут стать вашим секретным оружием в борьбе с переобучением, даже если вы уже используете передовые модели.
Регуляризация Тихонова: Более мягкая сила
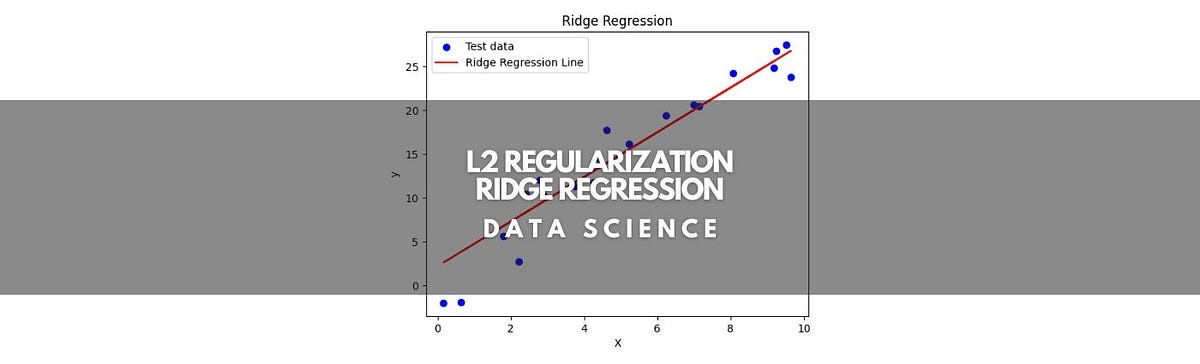
Регуляризация Тихонова (Tikhonov regularization), также известная как регуляризация Ridge, является вариацией L2 регуляризации, но с более “мягким” подходом. Вместо простого добавления штрафа за большую величину весов, она добавляет штраф, пропорциональный
квадрату
величины весов, плюс небольшое значение (λ) к диагонали матрицы правдоподобия. Это приводит к тому, что решение становится более стабильным и менее чувствительным к небольшим изменениям в данных.
Почему это может помочь?
Когда данные шумные или имеют мультиколлинеарность (сильная корреляция между признаками), обычная L2 регуляризация может привести к нежелательным эффектам, “отсекая” важные признаки. Тихонова регуляризация позволяет избежать этого, создавая более устойчивое решение, особенно при работе с матрицами, близкими к сингулярным.
Как применять?
В большинстве библиотек машинного обучения (например, scikit-learn) Тихонова регуляризация реализована как часть логистической регрессии или линейной регрессии. Ключевой параметр – это параметр
alpha
, который определяет силу регуляризации. Экспериментируйте с разными значениями
alpha
и оценивайте результаты на валидационном наборе данных.
Метод опорных векторов с ядром RBF: Поиск оптимального разделения
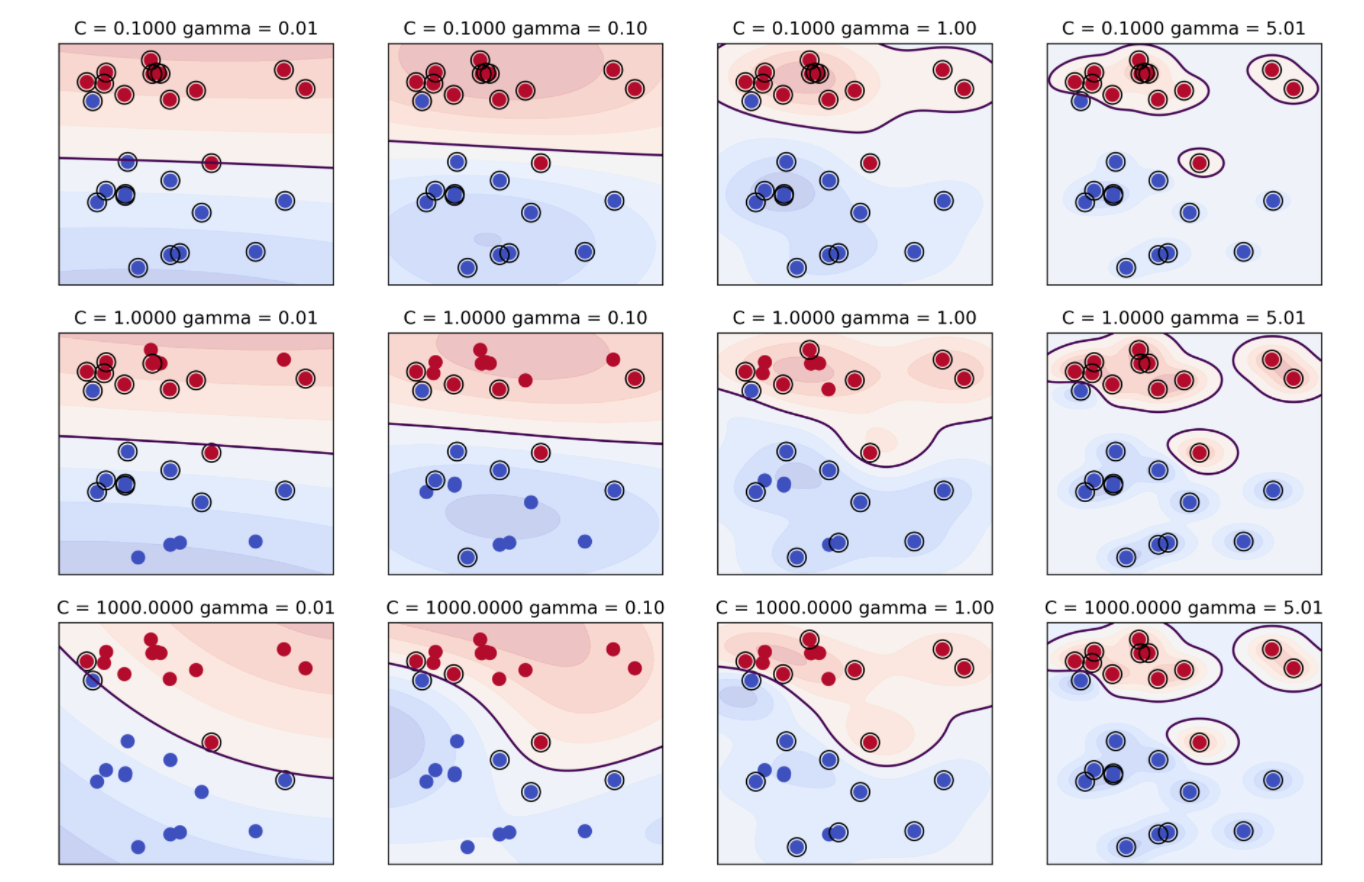
Метод опорных векторов (SVM) с ядром радиальных базисных функций (RBF) часто рассматривается как “черный ящик”, но его гибкость позволяет создавать сложные границы решений. Проблема заключается в подборе гиперпараметров: параметр γ (gamma) контролирует влияние отдельных точек данных, а параметр C – штраф за неправильную классификацию.
Почему это может помочь?
Ядро RBF позволяет создавать нелинейные границы решений, что полезно для сложных задач классификации. Правильный выбор γ и C позволяет избежать как недообучения (слишком простое решение), так и переобучения (слишком сложная модель). Важно отметить, что уменьшение гаммы (γ) обычно приводит к большей обобщающей способности.
Как применять?
Используйте кросс-валидацию для поиска оптимальных значений γ и C. Рассмотрите возможность использования методов оптимизации, таких как grid search или randomized search, для более эффективного поиска гиперпараметров.
Ансамбли деревьев с ограничением глубины: Контролируя сложность
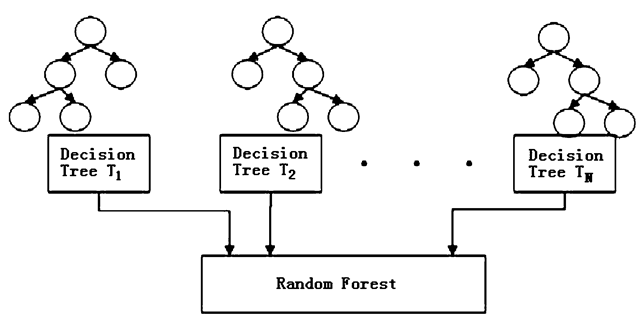
Случайный лес – мощный алгоритм, но его неконтролируемая сложность может привести к переобучению. Ограничение глубины деревьев (max_depth) – простой, но эффективный способ борьбы с этой проблемой.
Почему это может помочь?
Глубокие деревья склонны запоминать шум в данных. Ограничение глубины заставляет модель создавать более простые и обобщающие решения. Кроме того, можно использовать параметр
min_samples_split
для указания минимального количества выборок, необходимых для разделения узла.
Как применять?
Начните с небольших значений
max_depth
(например, 5 или 10) и постепенно увеличивайте их, наблюдая за изменениями в производительности на валидационном наборе данных. Попробуйте комбинировать это с регуляризацией по признакам (feature importance) для дальнейшего улучшения обобщающей способности.
Другие менее известные техники
Помимо вышеперечисленных, есть и другие техники, которые могут помочь в борьбе с переобучением:
-
Truncated SVD (Singular Value Decomposition):
Уменьшение размерности данных путем отбрасывания менее важных сингулярных значений. -
Elastic Net:
Комбинация L1 и L2 регуляризации, позволяющая сочетать преимущества обеих техник. -
Early Stopping:
Остановка обучения модели до того, как она начнет переобучаться.
Помните, что выбор конкретной техники зависит от особенностей вашего набора данных и задачи. Экспериментируйте, анализируйте результаты и не бойтесь пробовать новые подходы! Часто, комбинация нескольких техник дает наилучший результат.
Использование этих “забытых” техник машинного обучения может значительно улучшить производительность ваших моделей и повысить их обобщающую способность, помогая вам избежать распространенной проблемы переобучения.
#машинноеобучение #переобучение #регуляризация #svm #случайныйлес #датасайенс #AI #техникирегуляризации
Добавить комментарий