Эта статья глубоко погружается в квантование LLM, предлагая практическое руководство по выбору оптимальных методов (INT4, GPTQ, AWQ и другие) для максимального снижения размера модели и ускорения инференса, сохраняя при этом приемлемую точность. Мы рассмотрим нюансы каждой техники, предоставим реальные примеры и советы по настройке для различных аппаратных платформ, чтобы помочь вам добиться наилучшей производительности.
Введение в квантование LLM
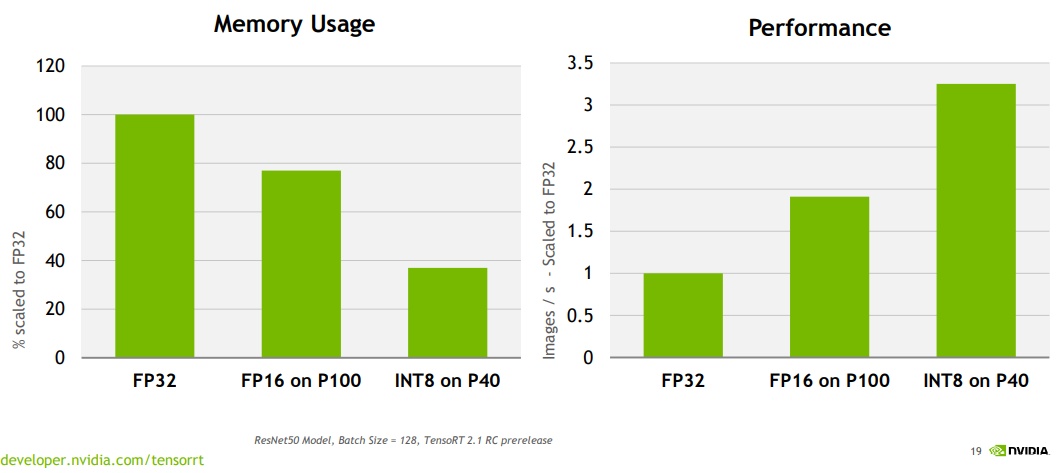
С ростом размера языковых моделей (LLM), таких как GPT-3, LLaMA и других, потребность в вычислительных ресурсах и памяти для их развертывания становится огромной проблемой. Квантование – это метод сжатия моделей, который значительно уменьшает размер модели и ускоряет инференс, снижая требования к памяти и вычислительной мощности. В своей сути, квантование заменяет числа с плавающей запятой (обычно FP16 или BF16) целыми числами меньшей разрядности (например, INT8, INT4). Это приводит к существенному сокращению размера модели (до 4 раз для перехода с FP16 на INT8) и ускорению вычислений, особенно на оборудовании, оптимизированном для целочисленных операций.
Основные методы квантования
INT8 Квантование
INT8 квантование – это самый простой и распространенный метод. Он заменяет числа с плавающей запятой 8-битными целыми числами. Этот метод относительно прост в реализации и обеспечивает хорошее ускорение на оборудовании, поддерживающем INT8 операции (например, NVIDIA Tensor Cores). Однако, потеря точности может быть заметной, особенно для сложных моделей.
INT4 Квантование
INT4 квантование идет дальше, используя 4-битные целые числа. Это приводит к еще большему сокращению размера модели и ускорению, но и увеличивает риск потери точности. Для успешного применения INT4 квантования требуются более сложные методы калибровки и постобработки.
GPTQ (Generative Post-training Quantization)
GPTQ – это метод постобработочного квантования, разработанный для минимизации потери точности при квантовании до INT4. Он использует метод минимизации ошибки, чтобы найти оптимальные шкалы и смещения для каждого слоя модели. GPTQ обычно обеспечивает лучшую точность, чем простое квантование INT4, но требует больше времени для калибровки.
AWQ (Activation-Aware Weight Quantization)
AWQ – это еще один метод постобработочного квантования, который фокусируется на активациях модели. Он определяет, какие веса наиболее чувствительны к квантованию, и сохраняет их в более высоком разрешении, в то время как менее важные веса квантуются сильнее. AWQ часто обеспечивает лучшую точность, чем GPTQ, особенно для больших моделей.
LLM.int8()
LLM.int8() – это метод, реализованный в библиотеке `auto-gptq`. Он использует динамическое квантование, где шкалы и смещения определяются во время инференса для каждого отдельного токена. Это позволяет адаптироваться к различным входным данным и улучшить точность, но может быть немного медленнее, чем статические методы.
Выбор подходящего метода квантования
Выбор метода квантования зависит от нескольких факторов, включая:
-
Требования к точности:
Если точность является критически важной, то стоит рассмотреть GPTQ или AWQ. -
Доступные вычислительные ресурсы:
GPTQ и AWQ требуют больше вычислительных ресурсов для калибровки. -
Поддержка оборудования:
Убедитесь, что ваше оборудование поддерживает выбранный метод квантования. -
Размер модели:
Для очень больших моделей AWQ часто показывает лучшие результаты.
Практические советы по настройке квантования
Вот несколько советов по настройке квантования для достижения наилучшей производительности:
-
Используйте репрезентативный набор данных для калибровки:
Набор данных для калибровки должен быть репрезентативным для данных, которые будут использоваться для инференса. -
Экспериментируйте с различными параметрами калибровки:
Разные методы квантования имеют разные параметры, которые можно настроить для оптимизации точности и скорости. -
Проверяйте точность после квантования:
Важно проверить точность модели после квантования, чтобы убедиться, что потеря точности приемлема. Используйте стандартные бенчмарки и метрики для оценки. -
Используйте библиотеки и инструменты:
Существуют различные библиотеки и инструменты, которые упрощают процесс квантования, такие как `auto-gptq`, `bitsandbytes` и `OptiML`.

Примеры использования и библиотеки
`auto-gptq`
: Предоставляет инструменты для квантования моделей GPTQ и GPTQ-for-AWQ.
`bitsandbytes`
: Библиотека для 8-битного квантования (INT8) и 4-битного квантования (NF4). Легко интегрируется с PyTorch.
`OptiML`
: Предоставляет инструменты для оптимизации и квантования моделей на различных платформах.
Заключение
Квантование является мощным инструментом для оптимизации производительности LLM. Выбор подходящего метода квантования и правильная настройка параметров могут значительно уменьшить размер модели, ускорить инференс и снизить требования к вычислительным ресурсам, сохраняя при этом приемлемую точность. Экспериментируйте с различными методами и настройками, чтобы найти оптимальное решение для ваших конкретных потребностей.
#LLM #Квантование #AI #ИскусственныйИнтеллект #Оптимизация #Производительность #GPTQ #AWQ #INT4 #AutoGPTQ
Добавить комментарий